2D Robot Simulation & Reinforcement Learning Platform
A complete robot simulation environment for differential drive robot navigation, localization, and reinforcement learning using IR-SIM (2D simulation). This project bridges classical robotics control algorithms with modern deep reinforcement learning, providing a hands-on learning platform for understanding both approaches. The system includes go-to-goal controllers, potential field navigation, odometry simulation, and full RL training pipeline with PPO, SAC, and TD3 algorithms—achieving 100% navigation success rate after implementing research-backed reward function design.
The Challenge
Robotics is often taught in isolation—either you learn classical control theory with differential equations and state-space models, or you dive into reinforcement learning with abstract environments like CartPole. But real-world robotics lives at the intersection of both worlds.
I wanted to build something that would:
- Make robot simulation accessible without expensive hardware or complex 3D physics engines
- Compare classical and learned approaches on the same navigation problems
- Document the journey of training an RL agent that actually works—including all the failures along the way
Architecture Overview
The platform is organized into three main layers:
1. Simulation Layer (IR-SIM)
IR-SIM (2D Intelligent Robot Simulator) provides the physics backbone:
- Differential Drive Kinematics: Accurate two-wheeled robot motion model with realistic velocity constraints
- World Configuration: YAML-based world files defining obstacles, boundaries, and robot properties
- Obstacle Types: Both circular and rectangular obstacles with proper collision detection
- Visualization: Real-time matplotlib rendering of robot trajectories and sensor readings
2. Classical Controllers
Before diving into RL, I implemented two classical navigation approaches:
Go-to-Goal Controller:
- Proportional control for heading alignment
- Obstacle avoidance using a 60° forward-facing detection cone
- Velocity modulation based on obstacle proximity
Potential Field Controller:
- Attractive potential toward the goal
- Repulsive potential from obstacles
- Gradient descent on the combined potential field
These controllers serve as baselines and help validate that the simulation environment works correctly.
3. Reinforcement Learning Pipeline
The RL system wraps IR-SIM with a Gymnasium-compatible environment:
Observation Space (7 values):
dx_norm, dy_norm: Normalized direction to goaldtheta: Heading error to goalv, w: Current linear and angular velocitydist_to_obstacle: Minimum distance to nearest obstacledistance_to_goal: Euclidean distance to goal
Action Space:
- Linear velocity:
[0.0, 1.0](forward-only constraint) - Angular velocity:
[-1.0, 1.0](turn left/right)
Training Algorithms:
- PPO (Proximal Policy Optimization) — primary
- SAC (Soft Actor-Critic)
- TD3 (Twin Delayed DDPG)
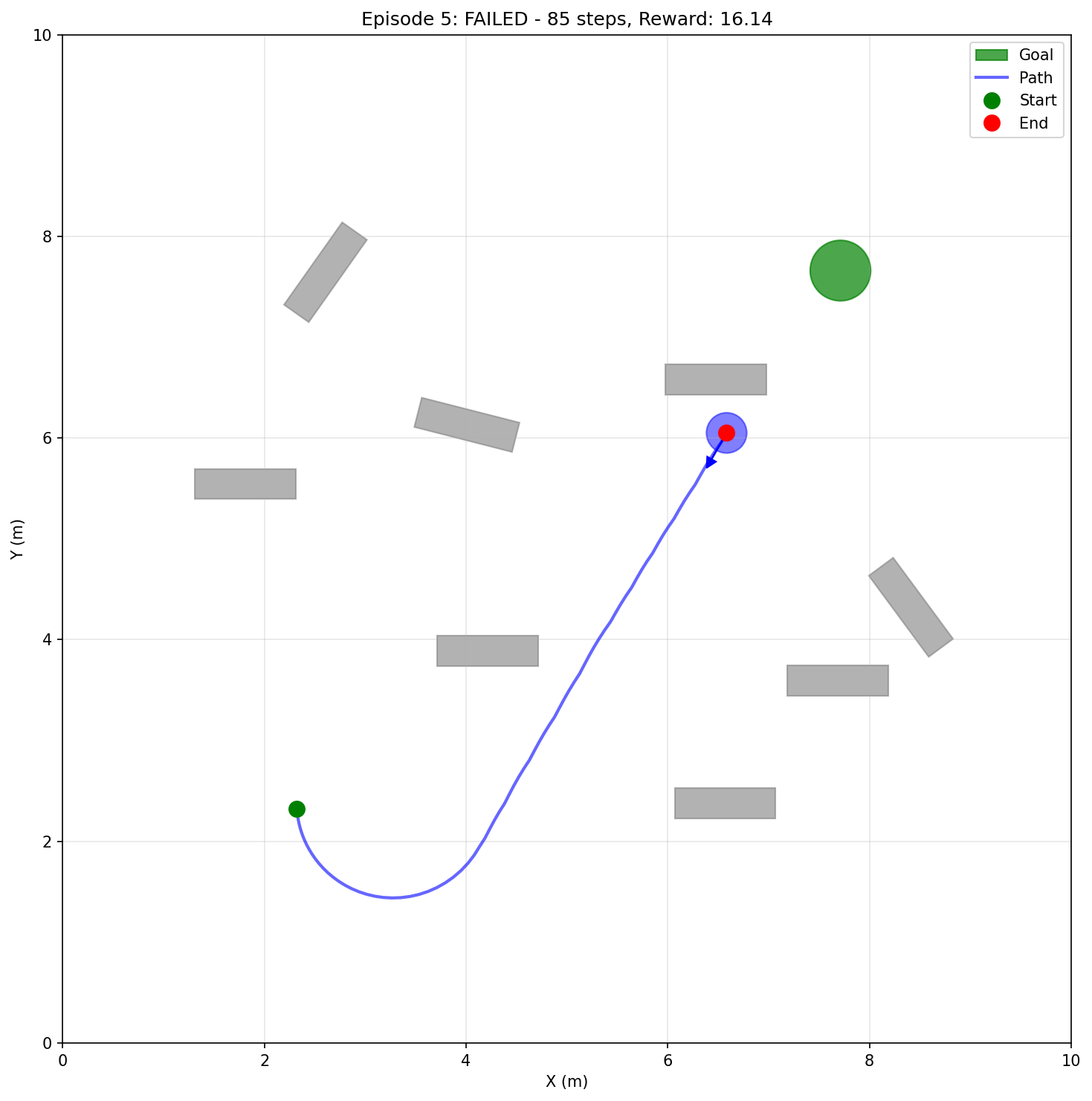
The Journey: From 0% to 100% Success Rate
Training the RL agent wasn't straightforward. Here's the honest story:
Initial Attempts: 20% Success Rate
My first version used a complex reward function with many competing signals:
- Distance-based rewards (inverse of distance to goal)
- Time penalties
- Movement bonuses
- Multiple obstacle proximity tiers
- Heading alignment rewards
The agent learned... to spin in circles. With 500,000 timesteps of training, it achieved only 20% success rate, and even those successes looked like luck rather than skill.
Root Cause Analysis
Deep diagnosis revealed several critical issues:
Issue 1: Action Space Mismatch
The action space allowed [-1.5, 1.5] velocities, but the robot config only supported [-1, 1]. The agent was learning invalid actions that got clipped—wasted training on impossible behaviors.
Issue 2: Collision Detection Bug
Using hasattr() instead of getattr() for IR-SIM shape objects caused silent failures. The obstacle detection was returning default values instead of actual distances. The agent was literally blind to obstacles.
Issue 3: Reward Signal Confusion Too many competing reward signals confused the learning process. The agent couldn't figure out what behavior was being rewarded.
The Research-Based Fix
After extensive literature review on RL navigation, I implemented:
-
Constrained Action Space: Forward-only movement
[0, 1]for linear velocity—matching the go-to-goal controller behavior -
Progress-Based Reward: Simple
10.0 × max(0, progress)instead of inverse distance—clear signal that rewards closing the gap -
Excessive Rotation Penalty:
-5.0 × (w - 0.8)when angular velocity exceeds 0.8—stops the spinning behavior -
Simplified Signal: Removed all competing bonuses and penalties, focused on the primary objective
Final Result: 100% Success Rate 🎉
- Success Rate: 5/5 (100%)
- Average Reward: 378.35 ± 8.67
- Average Episode Length: 202.4 ± 24.2 steps
- Average Progress: 9.21 ± 0.60 meters per episode
Technology Stack
Simulation & Robotics
- IR-SIM: 2D robot simulation with differential drive kinematics
- NumPy: Numerical computing for transformations and physics
- Matplotlib: Real-time visualization and trajectory plotting
Reinforcement Learning
- Gymnasium: Standard RL environment interface
- Stable-Baselines3: PPO, SAC, TD3 implementations
- PyTorch: Neural network backend with MPS/CUDA support
- TensorBoard: Training visualization and metrics
Development
- Python 3.11+: Modern Python with type hints
- YAML: Configuration files for worlds and robots
- Pytest: Testing framework for controllers
Project Structure
robot_sim/
├── configs/ # World configuration files
│ ├── simple_world.yaml # Basic test world
│ ├── rl_world.yaml # RL training world
│ └── rl_world_complex.yaml # Complex obstacle world
├── scripts/ # Python scripts
│ ├── 01_test_simulation.py # Basic simulation test
│ ├── 02_go_to_goal.py # Go-to-goal demo
│ ├── 03_potential_field.py # Potential field demo
│ ├── 04_odometry.py # Odometry visualization
│ ├── 05_rl_environment.py # Gymnasium wrapper
│ ├── 06_train_rl.py # RL training script
│ ├── 07_evaluate_rl.py # Model evaluation
│ └── ... # Diagnostic tools
├── models/ # Trained models (PPO/SAC/TD3)
└── logs/ # TensorBoard logs & visualizations
Key Learnings
1. Start with Classical Controllers
Before training RL, implement classical solutions. They validate your simulation, provide baselines, and their behavior informs RL design (e.g., forward-only constraint).
2. Debug Systematically
When RL fails, resist the urge to tune hyperparameters randomly. Instead:
- Verify environment physics
- Check observation values during episodes
- Ensure collision detection works
- Validate reward signals make sense
3. Simpler Rewards Are Better
Complex reward functions with many terms confuse the agent. Progress-based rewards with clear, consistent signals outperform elaborate multi-objective formulations.
4. Action Space Design Matters
Constraining the action space to match desired behavior prevents the agent from learning counterproductive strategies. If your robot shouldn't back up, don't allow negative linear velocity.
5. Document Everything
The most valuable output isn't the final model—it's the journey. The diagnostic scripts and change logs helped me understand what went wrong and why the fixes worked.
Running the Project
Quick Start
# Clone and setup git clone https://github.com/padawanabhi/robot_sim.git cd robot_sim python3 -m venv venv && source venv/bin/activate pip install -r requirements.txt # Test simulation python scripts/01_test_simulation.py # Train RL agent python scripts/06_train_rl.py --algorithm ppo --timesteps 500000 # Evaluate trained model python scripts/07_evaluate_rl.py --algorithm ppo --episodes 5
Monitor Training
tensorboard --logdir logs/tensorboard # Open http://localhost:6006
Future Improvements
- SLAM Integration: Add mapping capabilities with occupancy grids
- Multi-Robot Scenarios: Train agents for coordination and collision avoidance
- Sim-to-Real Transfer: Deploy learned policies to physical robots
- Curriculum Learning: Gradually increase obstacle density during training
- 3D Extension: Migrate concepts to Gazebo/Isaac Sim for 3D navigation
Resources
- GitHub Repository: padawanabhi/robot_sim
- IR-SIM Documentation: ir-sim.readthedocs.io
- Stable-Baselines3: stable-baselines3.readthedocs.io